O algoritmo LMS
O algoritmo steepest descent
Na regressão linear multivariada, conhecendo-se o conjunto de dados de treinamento
\[ \{(x_{11}, x_{21}, \cdots, x_{M1} ,d_1), (x_{12}, x_{22}, \cdots, x_{M2} ,d_2),\cdots, (x_{1N_t}, x_{2N_t}, \cdots, x_{MN_t} ,d_{N_t})\}, \]
obtém-se um modelo de hiperplano do tipo
\[ y=b+w_1x_1+w_2x_2+\cdots+w_Mx_M\approx d, \]
em que \(N_t\) é o número de dados utilizados no treinamento, \(b\) o viés (bias), \(d\) o sinal desejado, \(y\) a estimativa de \(d\), \(x_k\) o sinal de entrada e \(w_k\), \(k=1,\cdots, M\) os pesos do regressor.
Para obter o modelo, utilizamos os dados de treinamento e calculamos a solução
\[\begin{equation*} \fbox{$\displaystyle \mathbf{w}^{\rm o}=(\mathbf{X}^{\rm T}\mathbf{X})^{-1}\mathbf{X}^{\rm T}\mathbf{d} $} \end{equation*}\]
em que
\[ \mathbf{w}^{\rm o}=\left[ \begin{array}{c} b^{\rm o} \\ w_1^{\rm o} \\ \vdots \\ w_M^{\rm o} \\ \end{array} \right],\;\;\;\; \mathbf{X}=\left[ \begin{array}{ccccc} 1 & x_{11} & x_{21} & \cdots & x_{M1} \\ 1 & x_{12} & x_{22} & \cdots & x_{M2} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_{1N_t} & x_{2N_t} & \cdots & x_{MN_t} \\ \end{array} \right]\;\;\;\;\text{e}\;\;\;\; \mathbf{d} =\left[ \begin{array}{c} d_1 \\ d_2 \\ \vdots \\ d_{N_t} \\ \end{array} \right]. \]
A solução \(\mathbf{w}^{\rm o}\) minimiza a norma ao quadrado do vetor de erros, que aqui vamos denotar por \(J(\mathbf{w})\), ou seja,
\[ J(\mathbf{w})=\|\mathbf{e}\|^2=\|\mathbf{d}-\mathbf{X}\mathbf{w}\|^2, \]
de modo que \(\mathbf{w}^{\rm o}={\rm argmin}_{\mathbf{w}} J(\mathbf{w})\).
O vetor de pesos \(\mathbf{w}^{\rm o}\) pode ser obtido a partir de um treinamento iterativo, em que cada amostra \((x_{1n}, x_{2n}, \cdots, x_{Mn} ,d_n),\) \(n=1,2,\cdots, N_t\) é apresentada a um algoritmo por vez. Para obter esse algoritmo, vamos primeiramente denotar o vetor de pesos da iteração \(n\) por
\[ \mathbf{w}(n) = [\,b(n)\;w_1(n)\;\cdots\;w_M(n)\,]^{\rm T}. \]
Fazendo o mesmo com os dados de treinamento, teremos na iteração \(n\) o sinal desejado \(d(n)=d_n\), \(n=1,2,\cdots,N_t\) e o vetor de entrada
\[ \mathbf{x}(n)=[\,1\;x_{1n}\; x_{2n}\; \cdots\; x_{Mn}\,]^{\rm T}. \]
O sinal de “saída” desse regressor iterativo é então calculado como
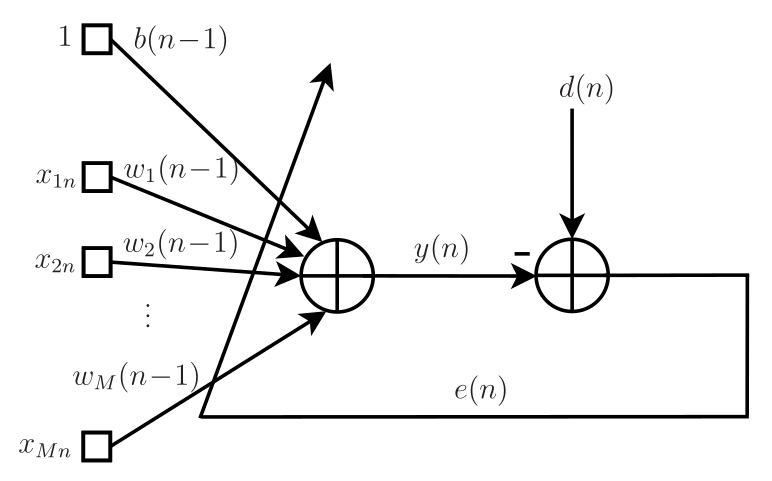
\[ y(n)=\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1)=b(n-1)+\sum_{k=1}^{M}x_{kn}w_k(n-1), \]
em que \(\mathbf{w}(0)=\mathbf{0}\). É importante observar que como se trata de um algoritmo iterativo, precisamos inicializar o vetor de pesos. Uma possibilidade é considerar o vetor nulo, embora também seja possível inicializar os pesos de forma aleatória.
Na regressão linear multivariada, o melhor hiperplano é obtido ao se minimizar o quadrado da norma do vetor de erros, ou seja, deve-se minimizar \(J(\mathbf{w})=\|\mathbf{e}\|^2\), que é comumente chamada de função custo. Aqui, devemos fazer algo semelhante. No entanto, não dispomos de um vetor de erros, pois estamos buscando a solução de forma iterativa, mas podemos calcular o erro de “estimação” em cada iteração, ou seja,
\[ e(n)=d(n)-y(n)=d(n)-\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1)=d(n)- b(n-1)-\sum_{k=1}^{M}x_{kn}w_k(n-1). \]
Assim, podemos ajustar os pesos para minimizar o erro quadrático médio (do inglês, mean-square error - MSE), definido como
\[ J_{\rm MSE}(\mathbf{w})={\rm E}\{e^2(n)\}, \]
em que \({\rm E}\{\cdot\}\) representa o operador esperança matemática. Para minimizar essa função, como no caso da regressão linear multivariada, devemos primeiramente derivá-la em relação ao vetor de pesos, o que leva ao vetor gradiente
\[ \begin{align*} \boldsymbol{\nabla}_{\mathbf{w}}J_{\rm MSE}(\mathbf{w}(n-1))&=\frac{\partial {\rm E}\{e^2(n)\}}{\partial \mathbf{w}(n-1)}=2{\rm E}\left\{e(n)\frac{\partial e(n)}{\partial \mathbf{w}(n-1)}\right\}= 2{\rm E}\left\{e(n)\left[\begin{array}{c} \frac{de(n)}{db(n-1)} \\ \\ \frac{de(n)}{dw_1(n-1)} \\ \vdots \\ \frac{de(n)}{dw_M(n-1)} \end{array} \right]\right\}\nonumber\\ &=2{\rm E}\left\{e(n)\left[\begin{array}{c} -1 \\ -x_{1n} \\ \vdots \\ -x_{Mn} \end{array} \right]\right\} =-2{\rm E}\{e(n)\mathbf{x}(n)\}. \end{align*} \]
Igualando o vetor gradiente ao vetor nulo, obtemos
\[ {\rm E}\{e(n)\mathbf{x}(n)\}={\rm E}\{\mathbf{x}(n)[d(n)-y(n)]\}=\boldsymbol{0}, \]
ou ainda
\[ {\rm E}\{\mathbf{x}(n)[d(n)-\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1)]\}=\boldsymbol{0}\Rightarrow \underbrace{{\rm E}\{\mathbf{x}(n)\mathbf{x}^{\rm T}(n)\}}_{\mathbf{R}}\mathbf{w}^{\rm wiener}=\underbrace{{\rm E}\{d(n)\mathbf{x}(n)\}}_{\mathbf{p}}. \]
A solução dessa equação leva ao MSE mínimo e é conhecida na literatura como solução de Wiener-Hopf, ou simplesmente, solução de Wiener. Por isso, vamos denotá-la como \(\mathbf{w}^{\rm wiener}\), ou seja,
\[\begin{equation*} \fbox{$\displaystyle \mathbf{w}^{\rm wiener}=\mathbf{R}^{-1}\mathbf{p}, $} \end{equation*}\]
em que \(\mathbf{R}\) é a matriz de autocorrelação dos dados de entrada e \(\mathbf{p}\) o vetor de correlação cruzada entre o sinal desejado \(d(n)\) e os dados de entrada. Tanto a matriz \(\mathbf{R}\) como o vetor \(\mathbf{p}\) têm em suas definições o operador esperança matemática. Podemos estimar \(\mathbf{R}\) e \(\mathbf{p}\) utilizando todos os dados de treinamento, o que leva respectivamente a
\[ \widehat{\mathbf{R}}=\frac{1}{N_t}\sum_{n=1}^{N_t}\mathbf{x}(n)\mathbf{x}^{\rm T}(n)\;\;\;\text{e}\;\;\;\widehat{\mathbf{p}}=\frac{1}{N_t}\sum_{n=1}^{N_t}d(n)\mathbf{x}(n). \]
Neste caso, a solução obtida com a regressão linear multivariada coincide com a solução de Wiener, ou seja, \(\mathbf{w}^{\rm o}=\mathbf{w}^{\rm wiener}\). Além disso, essa solução é única para um dado conjunto de treinamento.
Ao acompanhar esse cálculo, você pode estar se perguntando: onde está o algoritmo iterativo para o cálculo dos pesos? Ele pode ser obtido utilizando o método do gradiente. Em Cálculo, aprendemos que o gradiente de uma função aponta para a direção de maior variação da mesma. Como a solução é única, basta considerar o sentido contrário do gradiente, o que leva a
\[ \mathbf{w}(n)=\mathbf{w}(n-1)-\frac{\eta}{2}\boldsymbol{\nabla}_{\mathbf{w}}J_{\rm MSE}(\mathbf{w}(n-1)), \]
em que \(\eta\) é um passo de adaptação. Substituindo a expressão do gradiente, chega-se a
\[ \mathbf{w}(n)=\mathbf{w}(n-1)+\eta{\rm E}\{e(n)\mathbf{x}(n)\}, \]
ou ainda
\[ \mathbf{w}(n)=\mathbf{w}(n-1)+\eta{\rm E}\{\mathbf{x}(n)[d(n)-\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1)]\}. \]
Identificando a matriz \(\mathbf{R}\) e o vetor \(\mathbf{p}\) na equação acima, obtemos
\[\begin{equation*} \fbox{$\displaystyle \mathbf{w}(n)=\mathbf{w}(n-1)+\eta\left[\mathbf{p}-\mathbf{R}\mathbf{w}(n-1)\right]. $} \end{equation*}\]
Esse algoritmo iterativo é conhecido na literatura como steepest descent algorithm ou algoritmo do gradiente exato. O passo de adaptação \(\eta\) tem um papel fundamental em sua convergência. É possível demonstrar que se o intervalo \(0<\eta<2/{\lambda_{\max}}\) for atendido, em que \(\lambda_{\max}\) é o autovalor máximo da matriz \(\mathbf{R}\), essa equação converge exatamente para a solução de Wiener (Nascimento e Silva 2014),(Haykin 2014),(Sayed 2008). Apesar de chegar exatamente à solução que minimiza o MSE, ele não é adequado porque é necessário conhecer \(\mathbf{R}\) e \(\mathbf{p}\). A única vantagem é evitar calcular a inversa da matriz \(\mathbf{R}\), o que representa uma economia em custo computacional. Apesar de ser pouco utilizado na prática, esse algoritmo é fundamental para entendermos o algoritmo LMS a seguir.
O algoritmo LMS
Uma maneira de simplificar os cálculos para evitar ter de conhecer \(\mathbf{R}\) e \(\mathbf{p}\), é estimar essas grandezas instantâneamente, o que leva respectivamente a
\[ \widehat{\mathbf{R}}(n)=\mathbf{x}(n)\mathbf{x}^{{\rm T}}(n)\;\;\;\text{e}\;\;\;\widehat{\mathbf{p}}(n)=d(n)\mathbf{x}(n). \]
Substituindo essas aproximações no algoritmo steepest descent, chega-se a
\[\begin{equation*} \fbox{$\displaystyle \mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)\mathbf{x}(n), $} \end{equation*}\]
que é a equação de atualização do conhecido algoritmo LMS (least-mean-square), cujo pseudocódigo está mostrado no Algoritmo 1. O fluxo de sinal do LMS é mostrado na Figura 1. Novamente, o passo de adaptação \(\eta\) tem um papel fundamental na convergência desse algoritmo. Quanto menor o valor de \(\eta\), mais próximo da solução de Wiener o algoritmo LMS estará quando atingir o regime estacionário. No entanto, quanto menor o passo, mais lentamente o algoritmo atingirá o regime. Em contrapartida, passos grandes podem representar convergências rápidas, mas também podem levar o algoritmo à divergência. Neste caso, os pesos podem ir para infinito1. Diante disso, deve-se atentar ao compromisso entre precisão da solução e velocidade de convergência. O problema é que o intervalo \(0<\eta<2/{\lambda_{\max}}\) que vale para o algoritmo exato, é em geral maior do que o intervalo de passo admitido no algoritmo aproximado. Pode-se demonstrar que \(0<\eta<2/(3{\lambda_{\max}})\) é um intervalo mais razoável para o algoritmo LMS, mas ainda não garante sua convergência. Devido à sua simplicidade, ele é muito usado em diversas aplicações de filtragem adaptativa que exigem solução em tempo real. As principais aplicações incluem cancelamento de eco acústico, equalização de canais de comunicação, controle ativo de ruído e identificação de sistemas (Nascimento e Silva 2014),(Haykin 2014),(Sayed 2008).
Para finalizar esta seção, é importante observar que em várias aplicações de filtragem adaptativa não se considera o bias. Além disso, o vetor de entrada \(\mathbf{x}(n)\) muitas vezes é extraído de uma sequência de números, considerando uma linha de atrasos. Neste caso, ele é chamado de vetor regressor. Para exemplificar, vamos supor que temos a seguinte sequência de números
\[ \begin{array}{c} \vdots\\ x(n+1)=9\\ \;\;\;\;\;\;x(n)=1 \\ x(n-1)=2 \\ x(n-2)=3 \\ x(n-3)=4 \\ \!\!\!\!\!\vdots \end{array}, \]
em que \(n\) representa um instante de tempo ou uma posição. Considerando \(M=3\) e levando em conta a linha de atrasos sem o bias, os vetores de entrada do LMS nos instantes \(n-1\), \(n\) e \(n+1\) são dados respectivamente por
\[ \mathbf{x}(n-1)=[\,2\;\; 3\;\;4\,]^{{\rm T}},\;\;\;\mathbf{x}(n)=[\,1\;\; 2\;\;3\,]^{{\rm T}}\;\;\;\text{e}\;\;\;\mathbf{x}(n+1)=[\,9\;\; 1\;\;2\,]^{{\rm T}}. \]
Generalizando, tem-se
\[ \mathbf{x}(n)=[\,x(n)\;\;x(n-1)\;\;\cdots\;\;x(n-M+1)\,]^{{\rm T}}. \]
Para quem já estudou Processamento de Sinais, o LMS com esse vetor de entrada é um filtro com resposta ao impulso de duração finita (FIR - finite impulse response), cujos coeficientes variam ao longo do tempo.
Exemplo 1 Sumário do algoritmo LMS.
Inicialização: \(\mathbf{w}(0)=\boldsymbol{0}\)
Para \(n=1,2,\ldots,\) calcule:
\({y}(n)=\mathbf{x}^{{\rm T}}(n)\mathbf{w}(n-1)\)
\(e(n)=d(n)-y(n)\)
\(\mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)\mathbf{x}(n)\)
Fim
Exemplo de classificação com o LMS
Considere o exemplo de classificação das “meias-luas” da Figura 2. A meia-lua chamada de “Região A” está posicionada simetricamente em relação ao eixo \(x_2\), enquanto a meia-lua chamada de “Região B” está deslocada de \(r_1\) à direita do eixo \(x_2\) e de \(r_2\) abaixo do eixo \(x_1\). As duas meias-luas têm raio \(r_1\) e largura \(r_3\) idênticos. A distância vertical \(r_2\) que separa as duas meias-luas é ajustável e medida em relação ao eixo \(x_1\). Para \(r_2>0\), quanto maior o valor de \(r_2\), maior a separação entre as meias-luas. Já para \(r_2<0\), quando mais negativo for \(r_2\), mais próximas ficam as meias-luas (Haykin 2009).
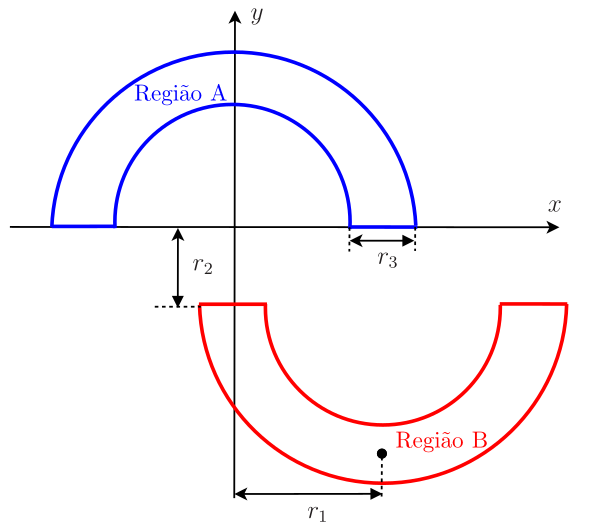
O conjunto de treinamento consiste em 5000 pontos, 2500 pertencentes à Região A e 2500 à Região B. Esses pontos são sorteados aleatoriamente. Assim, os pontos da Região A são sorteados considerando
\[ (\rho\cos\theta,\;\rho\,{\rm sen\,}\theta), \]
em que \(\theta\) é uma variável aleatória uniformemente distribuída no intervalo \([0,\;\pi]\) e \(\rho\) é outra variável aleatória uniformemente distribuída no intervalo \([r_1-r_3/2,\;\;r_1+r_3/2]\). Para essa região, considera-se que o sinal desejado é igual a um (\(d=1\)). Para gerar os pontos da Região B, basta considerar os deslocamentos, ou seja,
\[ (\rho\cos\theta+r_1,\;\;-\rho\,{\rm sen}\theta-r_2) \]
e \(d=-1\) como sinal desejado. O conjunto de teste consiste em 2000 pontos, 1000 pontos de cada região, gerados de forma independente do conjunto de treinamento.
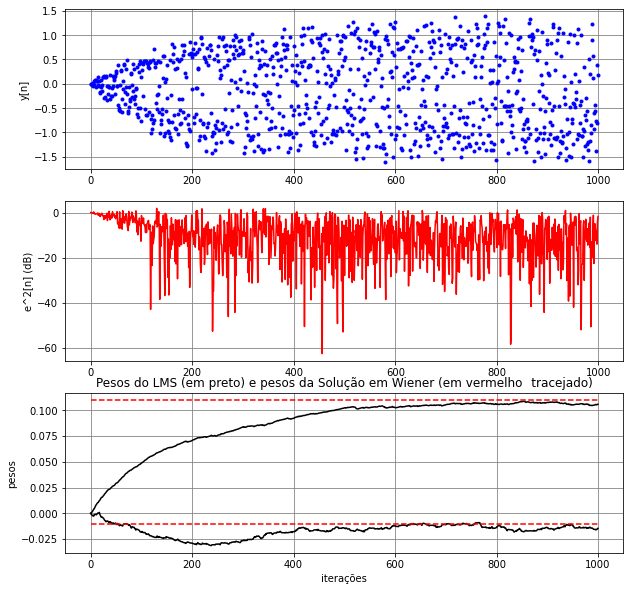
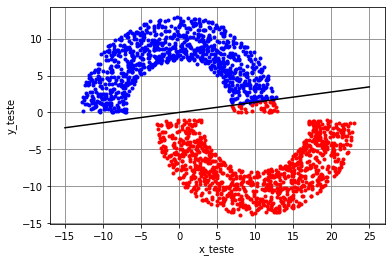
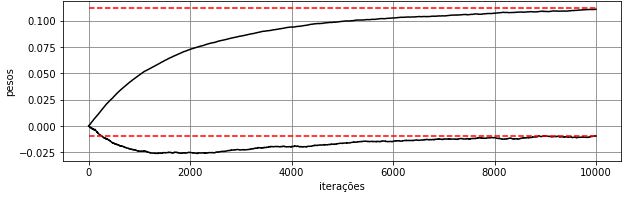
Para \(r_1=10\), \(r_2=1\) e \(r_3=6\), considerou-se o algoritmo LMS com passo \(\eta=10^{-3}\) e \(M=2\). Os dados de treinamento estão mostrados na Figura 3. Na Figura Figura 4, são mostrados a saída do algoritmo, o erro quadrático em dB e os pesos e bias ao longo das iterações. São mostrados também os pesos e bias da solução de Wiener (retas tracejadas em vermelho). Como esperado, os pesos e bias do algoritmo LMS se aproximam dos valores obtidos com a solução de Wiener, mas não convergem exatamente para eles. É possível observar que a velocidade de convergência dos pesos e bias do LMS são diferentes. O bias do LMS só atinge um valor próximo de
\(b=-0,086\) (bias da solução de Wiener) perto de \(n=5000\), enquanto os pesos chegam próximos dos de Wiener perto de \(n=200\). Em geral, não se usa o bias em aplicações de filtragem adaptativa. Considera-se esse parâmetro aqui apenas para obter um modelo de neurônio linear. A saída do LMS no treinamento não mostra uma separação clara entre os dois valores possíveis para o sinal desejado (\(\pm 1\)). Apesar disso, é possível verificar na Figura 5 com os dados de teste que há apenas uma pequena quantidade de dados da Região B que foram classificados erroneamente como pertencentes à Região A, o que leva a uma taxa de erro de aproximadamente 0,6%. Considerando os pesos da última iteração do LMS (\(n=5000\)), obtém-se a solução “linear” dada pela separação das regiões, mostrada na Figura 5.
Código
import numpy as np
import matplotlib.pyplot as plt
NA=2500 # número de pontos de treinamento da Região A
NB=2500 # número de pontos de treinamento da Região B
Nt=NA+NB # total de dados de treinamento
# dados das meia luas
r1=10
r3=6
r2=1
rmin=r1-r3/2
rmax=r1+r3/2
# Pontos da Região A
a=np.pi*np.random.rand(NA, 1)
rxy=np.random.uniform(rmin,rmax,(NA,1))
xA=rxy*np.cos(a)
yA=rxy*np.sin(a)
dA=np.ones((NA, 1))
pontosA=np.hstack((xA, yA, dA))
# Pontos da Região B
a=np.pi*np.random.rand(NB, 1)
rxy=np.random.uniform(rmin,rmax,(NB, 1))
xB=rxy*np.cos(a)+r1
yB=-rxy*np.sin(a)-r2
dB=-np.ones((NB, 1))
pontosB=np.hstack((xB, yB, dB))
#Concatenando e embaralhando os dados de treinamento
dados_treino=np.vstack((pontosA, pontosB))
np.random.shuffle(dados_treino)
# Figura para mostrar os dados de treino
fig, ax1 = plt.subplots()
ax1.plot(xA,yA,'.b')
ax1.plot(xB,yB,'.r')
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.grid(axis='x', color='0.5')
plt.grid(axis='y', color='0.5')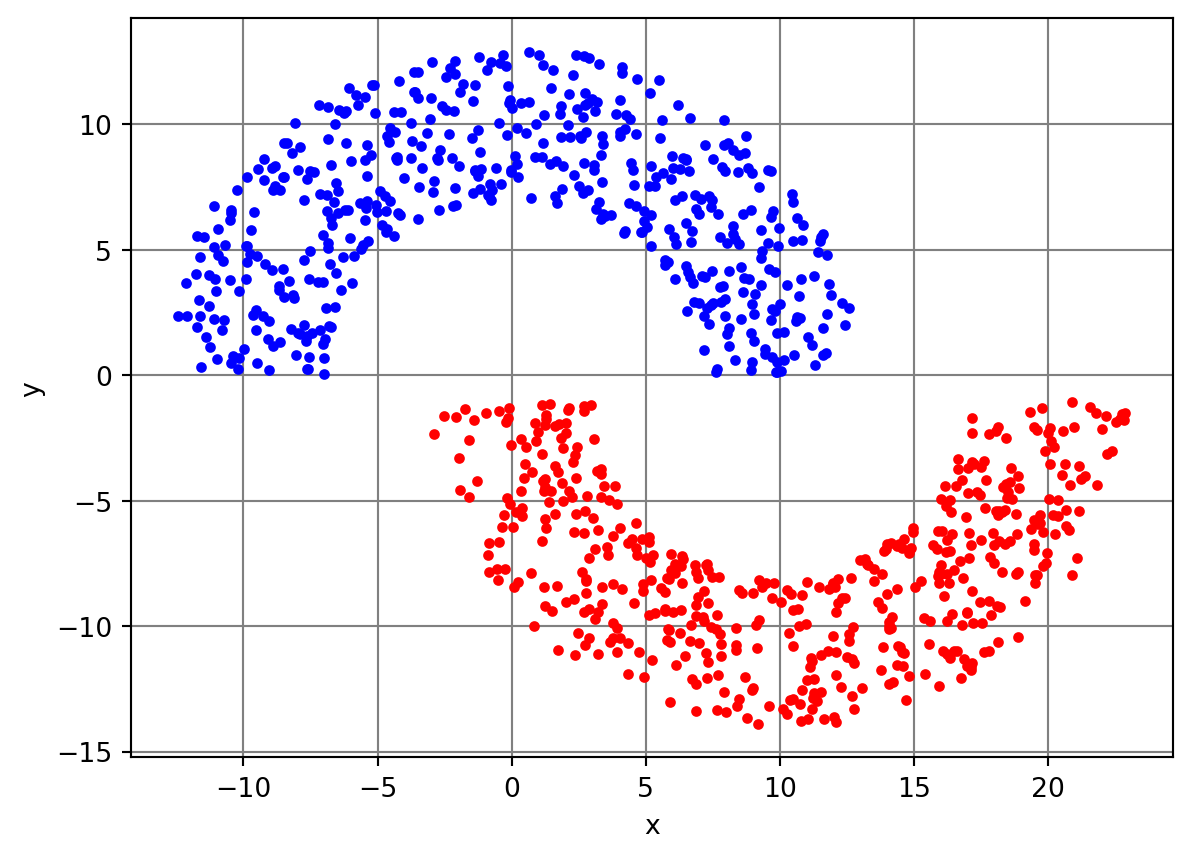
Ao diminuir o passo do algoritmo LMS para \(\eta=5\times 10^{-5}\), é possível observar na Figura 6 que o algoritmo LMS tem uma convergência mais lenta: os pesos levam cerca de \(n=10^3\) iterações para convergir enquanto o bias leva cerca de \(n=10^5\) iterações. Neste caso, foram considerados \(N_t=10^5\) dados de treinamento para que o algoritmo atingisse o regime permanente. Em contrapartida, a solução do algoritmo se torna mais próxima da de Wiener, como esperado. Assim, o projetista deve sempre ter em mente o compromisso entre passo de adaptação e precisão da solução. Apesar de mais precisa, a solução atingida ainda leva a erros na classificação como ocorre na Figura 5.
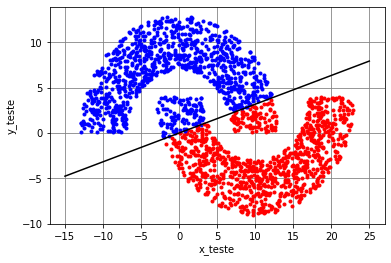
Considerando agora \(r_2=-4\), as meias-luas se tornam mais próximas, o que faz com que o algoritmo LMS chegue a uma solução que leva a mais erros: pontos da Região A são classificados erroneamente como pertencentes à Região B e vice-versa, como é possível observar na Figura 7. Neste caso, a taxa de erro aumenta para aproximadamente 11,5%. Para se obter uma solução sem erros para \(r_2=-4\), é necessário considerar um classificador não linear.
Época, batch, mini-batch e iteração
Em diversas aplicações, o banco de dados é limitado. Esse é o caso, por exemplo, do problema de classificação de arritmias cardíacas utilizando sinais de eletrocardiograma (ECG). A aquisição de novos sinais deve seguir o padrão do banco de dados existente: os sinais precisam ser amostrados com a mesma frequência, os sensores devem ser os mesmos, o exame deve seguir o mesmo protocolo etc. Vamos supor que seja possível garantir o mesmo padrão de aquisição dos sinais. Depois de serem adquiridos, os novos sinais de ECG precisam ser classificados por especialistas. Para manter o padrão, é ideal ter os mesmos especialistas que trabalharam na classificação dos sinais do banco de dados existente. Dá para notar que o aumento de alguns bancos de dados é complexo. Deve ser por isso que o banco de dados de ECG do MIT-BIH (Massachusetts Institute of Technology - Boston’s Beth Israel Hospital Arrhythmia Database) não recebe novos sinais desde 1980.
O que fazer quando a quantidade de dados é limitada e insuficiente para possibilitar a convergência dos algoritmos no treinamento? A solução é utilizar os dados de treinamento mais de uma vez. O treinamento realizado com o conjunto completo dos dados é chamado de época. Os algoritmos podem levar várias épocas até convergir. Como os dados utilizados em cada época são os mesmos, para gerar diversidade entre épocas, os dados de treinamento são misturados antes de se iniciar uma nova época (Haykin 2009).
O ajuste dos pesos do algoritmo LMS, descrito no Algoritmo 1, ocorre de maneira estocástica. O gradiente da função custo é estimado de maneira instantânea, a cada dado de treinamento. Assim, considerando uma época, haverá \(N_t\) atualizações dos pesos do LMS e o algoritmo minimiza o erro quadrático instantâneo, ou seja, \(\widehat{J}_{MSE}(\mathbf{w}(n-1))=e^2(n)\). Cabe definir aqui o conceito de iteração. A iteração do algoritmo ocorre toda vez que os pesos são atualizados. No caso estocástico, temos \(N_t\) iterações por época. Note que neste caso, o índice \(n\) coincide com iteração, pois o vetor de pesos é atualizado a cada \(n\), ou seja, a cada dado de treinamento. Essa forma de atualização estocástica é útil em problemas de tempo real, uma vez que a cada dado de entrada se deseja ter o dado de saída correspondente com o menor atraso possível. Em cancelamento de eco acústico, por exemplo, é essencial que isso ocorra para não gerar atrasos indesejados no sinal de voz. Neste tipo de aplicação, o treinamento ocorre junto com a inferência, ou seja, a saída e o erro calculados no treinamento são utilizados para atualizar os pesos e ao mesmo tempo para se obter a estimativa ou classificação desejada. No entanto, problemas de tempo real não são a maioria entre os problemas de aprendizado de máquina.
Em aprendizado de máquina, geralmente não estamos interessados em fazer a inferência durante o treinamento. A saída e o erro são utilizados no treinamento apenas para atualizar os pesos do algoritmo. Depois do treinamento, fixam-se os pesos para então se fazer a inferência e testar o classificador ou regressor. Por isso, vamos agora analisar outro caso extremo, em que todos os dados de treinamento são utilizados para estimar o vetor gradiente. Neste caso, o vetor de pesos será atualizado apenas uma vez a cada época. Portanto, teremos apenas uma iteração por época. Vamos supor que o vetor de pesos do LMS acabou de ser atualizado no final da época \(k-1\), ou seja, dispomos de \(\mathbf{w}(k-1)\). Assim, ele será atualizado novamente apenas no final da época \(k\). Durante a época \(k\), estima-se o vetor gradiente como
\[ \widehat{\boldsymbol{\nabla}}_{\mathbf{w}}J_{\rm MSE}(\mathbf{w}(k-1))=-\frac{2}{N_t}\sum_{n=1}^{N_t}\left[d(n)-\mathbf{x}^{{\rm T}}(n)\mathbf{w}(k-1)\right]\mathbf{x}(n). \]
Esse gradiente deve ser então utilizado no final da época \(k\) para atualizar \(\mathbf{w}(k-1)\), ou seja,
\[ \mathbf{w}(k)=\mathbf{w}(k-1)-\frac{\eta}{2}\widehat{\boldsymbol{\nabla}}_{\mathbf{w}}J_{\rm MSE}(\mathbf{w}(k-1)). \]
Na sequência, o vetor \(\mathbf{w}(k)\) é utilizado para estimar o gradiente na época \(k+1\) e assim sucessivamente. Essa forma de atualização do vetor de pesos é chamada de modo batch. Neste caso, o algoritmo LMS busca minimizar em cada época a seguinte aproximação da função custo:
\[ \widehat{J}_{MSE}(\mathbf{w}(k-1))=\frac{1}{N_t}\sum_{n=1}^{N_t}{e_{k-1}^2(n)}=\frac{1}{N_t}\sum_{n=1}^{N_t}[d(n)-\mathbf{x}^{{\rm T}}(n)\mathbf{w}(k-1)]^2, \]
em que \(k=1,2,\cdots,N_e\), sendo \(N_e\) o número de épocas.
Cabem aqui algumas observações:
- O treinamento em modo batch não é utilizado em aplicações de tempo real, pois gera um atraso inaceitável em aplicações desse tipo.
- O índice \(n\) neste modo de treinamento não representa iteração e sim a posição do dado no conjunto de treinamento. Dessa forma, para \(n=5\) temos \(\mathbf{x}(5)\), que representa o quinto dado do conjunto de treinamento, que por sua vez, contém ao todo \(N_t\) dados.
- Como os dados são misturados de uma época para outra, o vetor \(\mathbf{x}(5)\) da época \(k\) pode ser o vetor \(\mathbf{x}(200)\) da época \(k-1\).
- Na formulação anterior, a iteração foi representada por \(k\), que coincide com as épocas do treinamento.
- Os índices \(k-1\) e \(n\) no erro \(e_{k-1}(n)\) foram utilizados para indicar que ele é calculado com o vetor de pesos \(\mathbf{w}(k-1)\) e com os dados de treinamento \(\mathbf{x}(n)\) e \(d(n)\) da posição \(n\), respectivamente.
Dadas essas observações, na formulação do modo de treinamento batch, é mais conveniente usar a notação matricial, similar à da regressão linear multivariada. Assim, definindo-se na iteração (ou época) \(k\) os vetores
\[ \mathbf{w}(k-1)=\left[ \begin{array}{c} b(k-1) \\ w_1(k-1) \\ \vdots \\ w_M(k-1) \\ \end{array} \right],\;\;\;\; \mathbf{d}(k) =\left[ \begin{array}{c} d(1) \\ d(2) \\ \vdots \\ d(N_t) \\ \end{array} \right], \;\;\;\; \mathbf{e}(k) =\left[ \begin{array}{c} e_{k-1}(1) \\ e_{k-1}(2) \\ \vdots \\ e_{k-1}(N_t) \\ \end{array} \right] \]
e a matriz
\[ \mathbf{X}(k)=\left[\begin{array}{c} \mathbf{x}^{{\rm T}}(1) \\ \mathbf{x}^{{\rm T}}(2) \\ \vdots \\ \mathbf{x}^{{\rm T}}(N_t) \end{array} \right]= \left[ \begin{array}{ccccc} 1 & x_{11} & x_{21} & \cdots & x_{M1} \\ 1 & x_{12} & x_{22} & \cdots & x_{M2} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_{1N_t} & x_{2N_t} & \cdots & x_{MN_t} \\ \end{array} \right], \]
pode-se calcular o vetor de erros \(\mathbf{e}(k)\) como
\[ \mathbf{e}(k)=\mathbf{d}(k)-\mathbf{X}(k)\mathbf{w}(k-1), \]
e a estimativa do vetor gradiente como
\[ \widehat{\boldsymbol{\nabla}}_{\mathbf{w}}J_{\rm MSE}(\mathbf{w}(k-1))=-\frac{2}{N_t}\mathbf{X}^{{\rm T}}(k)\mathbf{e}(k). \]
Essa estimativa do gradiente leva à seguinte atualização dos pesos:
\[\begin{equation*} \fbox{$\displaystyle \mathbf{w}(k)=\mathbf{w}(k-1)+\frac{\eta}{N_t}\mathbf{X}^{{\rm T}}(k)\mathbf{e}(k). $} \end{equation*}\]
Com essa notação, a aproximação da função custo que o LMS busca minimizar a cada época neste modo pode ser reescrita como
\[ \widehat{J}_{MSE}(\mathbf{w}(k-1))=\frac{1}{N_t}\|\mathbf{e}(k)\|^2. \]
Como o treinamento em modo batch não é utilizado em aplicações de tempo real e todos os dados de treinamento estão disponíveis, é mais eficiente atualizar os pesos de forma matricial, o que permite que as contas sejam feitas em paralelo. Na formulação não matricial, o erro \[e_{k-1}(n)=d(n)-\mathbf{x}^{{\rm T}}(n)\mathbf{w}(k-1)\]
é calculado para cada dado de treinamento e utilizado no cálculo \(e_{k-1}(n)\mathbf{x}(n)\) para estimar o gradiente em um loop, o que torna o cálculo ineficiente.
Ainda é possível encontrar uma solução intermediária. Considere que, em toda época, os dados de treinamento sejam divididos em conjuntos de tamanho \(N_b<N_t\), que é chamado na literatura de tamanho do mini-batch. Neste caso, teremos \(N_{mb}\triangleq \lfloor N_t/N_b \rfloor\) conjuntos de dados a cada época2. Considere que o algoritmo utilize cada um desses conjuntos para estimar o vetor gradiente e com essa estimativa atualize os pesos. Dessa forma, os pesos serão atualizados \(N_{mb}\) vezes por época, a cada \(N_b\) dados de treinamento. Em outras palavras, o algoritmo terá \(N_{mb}\) iterações por época. Apesar dos pesos serem atualizados mais vezes por época que no modo de treinamento batch, o modo mini-batch também não é usado em aplicações de tempo real, o que faz com que a formulação matricial seja mais eficiente. Assim, na iteração \(m\), vamos definir os vetores
\[ \mathbf{w}(m-1)=\left[ \begin{array}{c} b(m-1) \\ w_1(m-1) \\ \vdots \\ w_M(m-1) \\ \end{array} \right],\;\;\;\; \mathbf{d}(\ell) =\left[ \begin{array}{c} d({\ell N_b+1}) \\ d({\ell N_b+2}) \\ \vdots \\ d({\ell N_b+ N_b}) \\ \end{array} \right], \;\;\;\; \mathbf{e}_{m-1}(\ell) =\left[ \begin{array}{c} e_{m-1}({\ell N_b+1}) \\ e_{m-1}({\ell N_b+2}) \\ \vdots \\ e_{m-1}({\ell N_b+N_b}) \\ \end{array} \right] \]
e a matriz
\[ \mathbf{X}(\ell)=\left[\begin{array}{c} \mathbf{x}^{{\rm T}}(\ell N_b+1) \\ \mathbf{x}^{{\rm T}}(\ell N_b+2) \\ \vdots \\ \mathbf{x}^{{\rm T}}(\ell N_b+N_b) \end{array} \right]= \left[ \begin{array}{ccccc} 1 & x_{1(\ell N_b+1)} & x_{2(\ell N_b+1)} & \cdots & x_{M(\ell N_b+1)} \\ 1 & x_{1(\ell N_b+2)} & x_{2(\ell N_b+2)} & \cdots & x_{M(\ell N_b+2)} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_{1(\ell N_b+N_b)} & x_{2(\ell N_b+N_b)} & \cdots & x_{M(\ell N_b+N_b)} \\ \end{array} \right], \]
em que \(m=1, 2, \cdots, N_eN_{mb}\) e \(\ell=0, 1, 2, \cdots, N_{mb}-1\). Diferente do modo de treinamento batch, iteração no modo mini-batch não coincide com época. Em cada época, temos \(N_{mb}\) iterações. Portanto, considerando \(N_e\) épocas, teremos \(N_eN_{mb}\) iterações no total3.
Utilizando essas definições, o vetor de erros é dado por
\[ \mathbf{e}_{m-1}(\ell)=\mathbf{d}(\ell)-\mathbf{X}(\ell)\mathbf{w}(m-1) \]
e a estimativa do vetor gradiente por
\[ \widehat{\boldsymbol{\nabla}}_{\mathbf{w}}J_{\rm MSE}(\mathbf{w}(m-1))=-\frac{2}{N_b}\mathbf{X}^{{\rm T}}(\ell)\mathbf{e}_{m-1}(\ell). \]
Essa estimativa do gradiente leva à seguinte atualização dos pesos:
\[\begin{equation*} \fbox{$\displaystyle \mathbf{w}(m)=\mathbf{w}(m-1)+\frac{\eta}{N_b}\mathbf{X}^{{\rm T}}(\ell)\mathbf{e}_{m-1}(\ell). $} \end{equation*}\]
Por fim, a aproximação da função custo que o LMS busca minimizar a cada mini-batch pode ser escrita como
\[ \widehat{J}_{MSE}(\mathbf{w}(m-1))=\frac{1}{N_b}\|\mathbf{e}_{m-1}(\ell)\|^2. \]
É muito comum na literatura usar o modo mini-batch, já que se obtém uma melhor estimativa do gradiente e consequentemente uma melhor precisão para se alcançar o mínimo da função custo em comparação com o caso estocástico e um menor custo computacional em comparação com o modo batch. O pseudocódigo do algoritmo LMS no modo mini-batch está no Algoritmo 2. Observe que \(N_b=1\) leva ao modo de treinamento estocástico e \(N_b=N_t\) ao modo batch.
Exemplo 2 Sumário do algoritmo LMS com mini-batch. \(N_e\) é o número de épocas, \(N_b\) o tamanho do mini-batch, \(N_t\) o número de dados de treinamento e \(N_{mb}= \lfloor N_t/N_b \rfloor\) o número de mini-batches por época.
Inicialização: \(\mathbf{w}(0)=\boldsymbol{0}\)
Para \(k=1,2,\ldots, N_e\), calcule:
Misture os dados de treinamento
Organize os dados na matriz \(\mathbf{X}(\ell)\) e no vetor \(\mathbf{d}(\ell)\) para \(\ell=0, 1,2,\ldots, N_{mb}-1\)
Para \(\ell=0, 1,2,\ldots, N_{mb} - 1\) calcule:
\(m=(k-1)N_{mb}+\ell+1\)
\(\mathbf{e}_{m-1}(\ell)=\mathbf{d}(\ell)-\mathbf{X}(\ell)\mathbf{w}(m-1)\)
\(\mathbf{w}(m)=\mathbf{w}(m-1)+\displaystyle\frac{\eta}{N_b}\mathbf{X}^{\rm T}(\ell)\mathbf{e}_{m-1}(\ell)\)
Fim
Fim
Exemplo do LMS nos três modos de treinamento
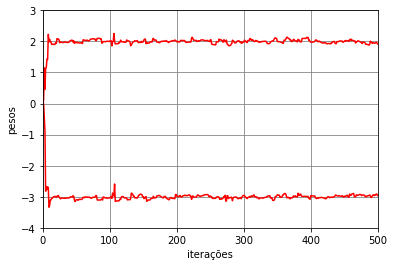
Para exemplificar os três modos de treinamento do LMS, vamos considerar novamente o problema de classificação das meias-luas. No modo de treinamento estocástico com \(\eta=10^{-3}\), \(N_t=5000\), \(N_e=1\) e \(N_b=1\). Os pesos e bias ao longo das iterações estão mostrados na Figura 8. Pode-se observar que esses parâmetros se aproximam dos valores obtidos com a solução de Wiener, mas como a estimativa do gradiente é instantânea, ocorrem variações em torno desses valores ótimos. No caso, como consideramos apenas uma época, temos \(5000\) iterações, valor que coincide com o número de dados de treinamento.
Vamos agora considerar o algoritmo LMS no modo de treinamento mini-batch com \(\eta=10^{-3}\), \(N_t=5000\), \(N_e=100\) e \(N_b=20\). Os pesos e bias ao longo das iterações estão mostrados na Figura 9. Pode-se observar que os pesos variam menos em torno dos valores ótimos em comparação com o caso estocástico. Isso ocorre, pois a estimativa do gradiente é feita a cada \(N_b=20\) dados do conjunto de treinamento. Como foram consideradas \(100\) épocas, temos \(N_e\lfloor N_t/N_b\rfloor=25000\) iterações.
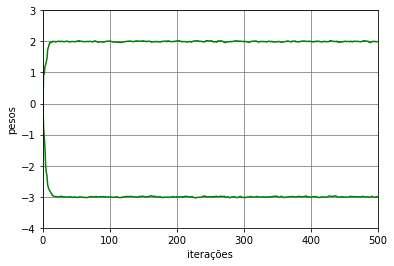
Considerando agora o algoritmo LMS no modo de treinamento batch com \(\eta=10^{-2}\), \(N_t=5000\), \(N_e=1000\) e \(N_b=5000\), os pesos e bias ao longo das iterações estão mostrados na Figura 10. Como o gradiente é estimado a cada época com todos os dados de treinamento, os pesos convergem exatamente para os valores ótimos. Como foram consideradas \(1000\) épocas, temos \(1000\) iterações.
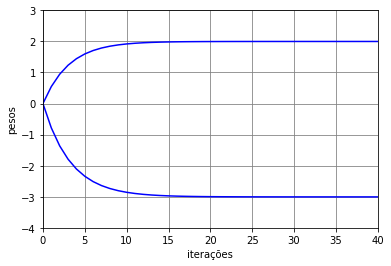
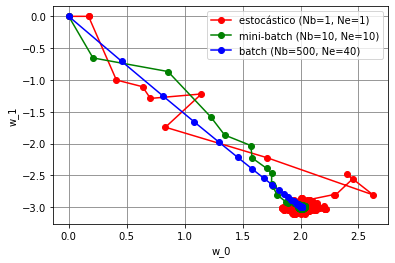
As trajetórias dos pesos do algoritmo LMS nesses três modos de treinamento estão mostradas na Figura 11. Pelas trajetórias, é possível ver que o caminho do batch é mais direto e atinge exatamente a solução ótima. Já o caminho do mini-batch é menos direto e varia mais em torno da solução ótima. Por fim, o estocástico é o que mais varia ao longo do caminho e também quando se aproxima da solução ótima. Comparando esses três modos de treinamento, o modo mini-batch é o que apresenta o melhor compromisso entre custo computacional e precisão da resposta e por isso é o mais utilizado em aplicações de aprendizado de máquina.
Referências
Notas de rodapé
Infinito aqui significa valor acima do maior valor representável em um software numérico ou hardware.↩︎
Considera-se o arredondamento para baixo para que o número de conjuntos de dados por época seja sempre inteiro. Assim, por exemplo, se \(N_t=1233\) e \(N_b=50\), consideram-se \(N_{mb}=24\) conjuntos com \(50\) dados por época. Como os dados são misturados a dada época, os \(33\) dados desprezados em uma determinada época aparecerão em outras.↩︎
Diferente também do caso batch, inserimos aqui o índice \(m-1\) ao vetor de erros \(\mathbf{e}_{m-1}(\ell)\). Isso foi feito porque o índice \(\ell\) se repete em cada época e não coincide com a iteração. Por exemplo, podemos ter \(\mathbf{e}_{200}(5)\) e \(\mathbf{e}_{50}(5)\). No cálculo do primeiro vetor se utiliza \(\mathbf{w}(200)\), enquanto no do segundo se utiliza \(\mathbf{w}(50)\). Ambos os vetores são calculados com dados da posição \(5N_b+1\) à posição \(5N_b+N_b\). Apesar disso, os dados não são necessariamente os mesmos porque eles são misturados antes do início de cada época.↩︎