O modelo do neurônio
O perceptron de Rosenblatt
Para introduzir o perceptron de Rosenblatt, vamos voltar ao exemplo das meias-luas, em que o algoritmo LMS foi utilizado para classificar os dados como pertencentes à Região A ou Região B, como mostrado na Figura 1, repetida aqui por conveniência.
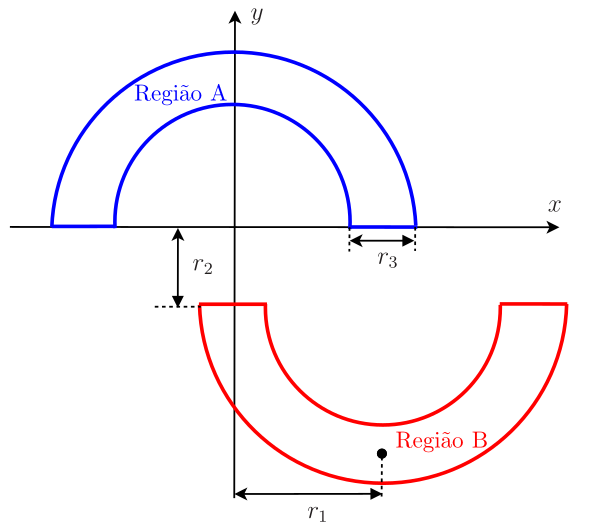
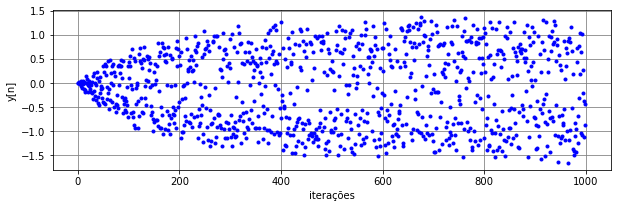
Para \(r_1=10\), \(r_2=1\), \(r_3=6\), \(\mu=10^{-3}\) e \(M=2\), a saída do LMS no modo estocástico (\(N_t=5000\), \(N_b=1\) e \(N_e=1\)) está mostrada na Figura Figura 2. Nesta aplicação, considerou-se como sinal desejado \(d=+1\) para dados pertencentes à Região A e \(d=-1\) para os pertencentes à Região B. Com os pesos e bias da última iteração, o LMS consegue classificar os dados com uma taxa de erros de aproximadamente 0,6% por meio de uma separação linear entre as regiões. Apesar disso, a saída do algoritmo fica espalhada no intervalo \([-1,\!5\;\; 1,\!5],\) não havendo uma clara separação em torno do zero.
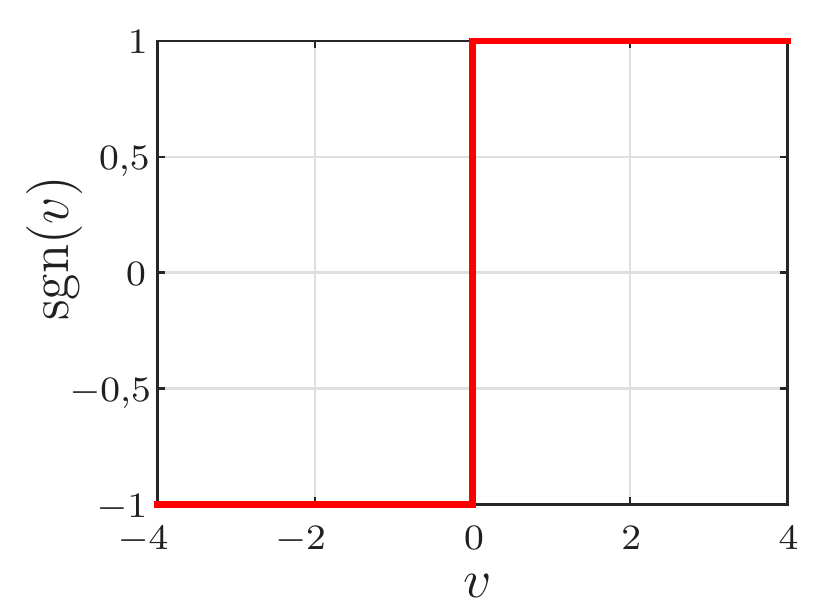
Diferente do LMS, o perceptron de Rosenblatt força a saída \(y(n)\) a assumir valores do conjunto \(\{-1,\; +1\}.\) Para isso, ele introduz uma função não linear \(\varphi(\cdot)\) à saída do combinador. No caso, a função \(\varphi(\cdot)\) é um limitador abrupto (hard limiter), dado por
\[ \varphi(v)=\text{sgn}(v)=\left\{\begin{array}{cc} +1, & v\geq 0 \\ -1, & v<0 \end{array}, \right. \]
em que \(\text{sgn}(\cdot)\) representa a função sinal, como mostrado na Figura 3.
Considerando o \(n\)-ésimo vetor dos dados de treinamento
\[ \mathbf{x}(n)=[\,1\;x_{1n}\; x_{2n}\; \cdots\; x_{Mn}\,]^{\rm T} \]
e o vetor de pesos e bias com dimensão \(M+1\)
\[ \mathbf{w}(n) = [\,b(n)\;w_1(n)\;\cdots\;w_M(n)\,]^{\rm T}, \]
a saída do combinador linear pode ser escrita como
\[ v(n) = \mathbf{x}^{\rm T}(n)\mathbf{w}(n-1) \]
e a saída do perceptron de Rosenblatt é dada por
\[ y(n)=\varphi(v(n))=\text{sgn}(v(n)). \]
Observe que devido à função sinal, \(y(n)\in \{-1,\;+1\}\). O diagrama de fluxo de sinal do perceptron de Rosenblatt está mostrado na Figura 4.
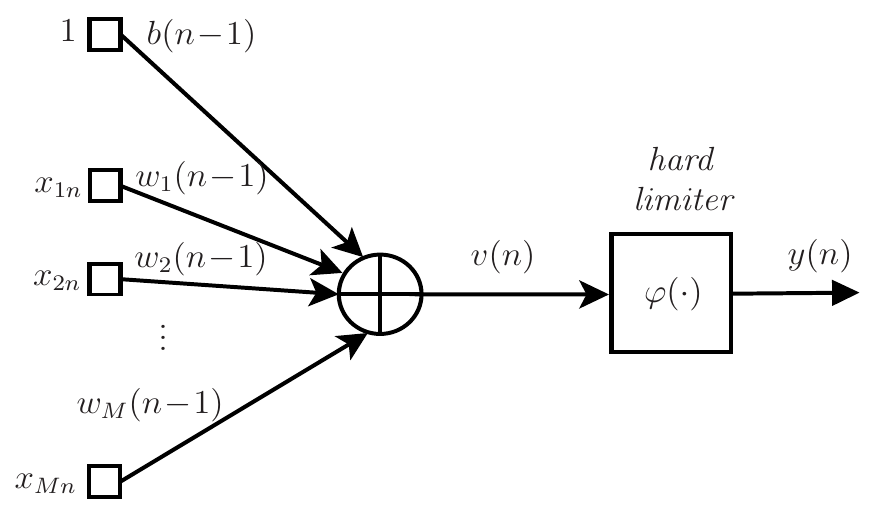
Como no algoritmo LMS, os pesos são atualizados para minimizar o erro quadrático \(e^2(n)\), em que
\[ e(n)=d(n)-\varphi(\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1))=d(n)-{\text{sgn}}(v(n))=d(n)-y(n). \]
Observe que \(e(n)\) assume agora três valores possíveis: \(-2\) ou \(+2\) quando \(d(n)\neq y(n)\) e \(0\) quando \(d(n)=y(n)\). Como a função sinal não é derivável em todos os pontos, não é possível obter o algoritmo de maneira formal, como feito na dedução do algoritmo LMS. Além disso, note que
\[ \frac{\partial e(n)}{\partial \mathbf{w}(n-1)}=-\frac{\partial \text{sgn}(\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1))}{\partial \mathbf{w}(n-1)}=-\mathbf{x}(n)\,{\text{sgn}'}(v(n))=\left\{\begin{array}{cc} \boldsymbol{0}, & v(n)\neq 0 \\ \nexists, & v(n)=0. \\ \end{array} \right. \]
Ignorando o fato da derivada não existir para \(v(n)=0\), os pesos não seriam atualizados se utilizássemos esse resultado, uma vez que o vetor gradiente é nulo para \(v(n)\neq 0\). Por isso, utiliza-se a equação de atualização
\[ \mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)\mathbf{x}(n). \]
Assim, os pesos são atualizados apenas quando \(e(n)\neq 0\), ou seja, quando \(y(n)\neq d(n)\). Caso contrário, \(\mathbf{w}(n)=\mathbf{w}(n-1)\). O passo de adaptação \(\eta\), também chamado de taxa de aprendizado, é uma constante positiva que deve ser escolhida no intervalo \(0<\eta\leq 1\). Como no caso do LMS, a escolha desse passo deve sempre levar em conta o compromisso entre estimativas mais precisas dos pesos e velocidade de aprendizado. A prova de convergência desse algoritmo para \(\eta=1\) pode ser encontrada, por exemplo, em (Haykin 2009). Considerando a formulação matricial e o modo de treinamento mini-batch1, o pseudocódigo do algoritmo de treinamento do perceptron de Rosenblatt é mostrado no Algoritmo 1.
Exemplo 1 Sumário do algoritmo de treinamento do perceptron de Rosenblatt no modo mini-batch. \(N_e\) é o número de épocas, \(N_b\) o tamanho do mini-batch, \(N_t\) o número de dados de treinamento e \(N_{mb}= \lfloor N_t/N_b \rfloor\) o número de mini-batches por época.
Inicialização: \(\mathbf{w}(0)=\boldsymbol{0}\)
Para \(k=1,2,\ldots, N_e\), calcule:
Misture os dados de treinamento
Organize os dados na matriz \(\mathbf{X}(\ell)\) e no vetor \(\mathbf{d}(\ell)\) para \(\ell=0, 1,2,\ldots, N_{mb}-1\)
Para \(\ell=0, 1,2,\ldots, N_{mb} - 1\) calcule:
\(m=(k-1)N_{mb}+\ell+1\)
\(\mathbf{v}_{m-1}(\ell)=\mathbf{X}(\ell)\mathbf{w}(m-1)\)
\(\mathbf{y}_{m-1}(\ell)=\text{sgn}(\mathbf{v}_{m-1}(\ell))\)
\(\mathbf{e}_{m-1}(\ell)=\mathbf{d}(\ell)-{\mathbf y}_{m-1}(\ell)\)
\(\mathbf{w}(m)=\mathbf{w}(m-1)+\displaystyle\frac{\eta}{N_b}\mathbf{X}^{\rm T}(\ell)\mathbf{e}_{m-1}(\ell)\)
Fim
Fim
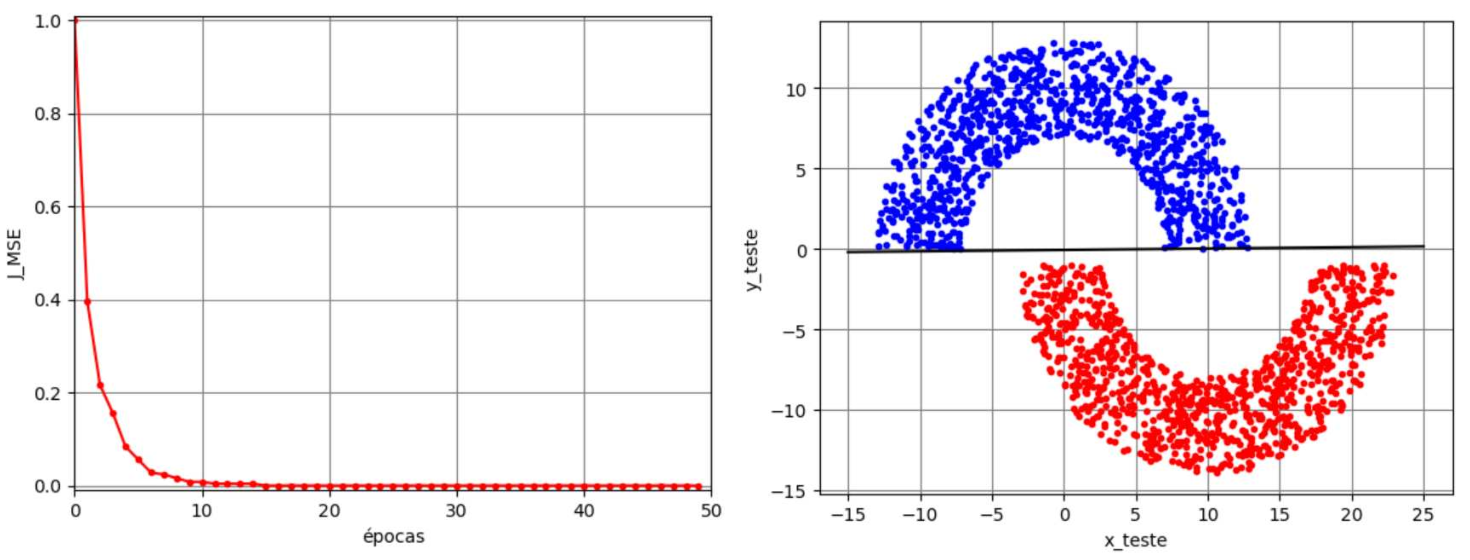
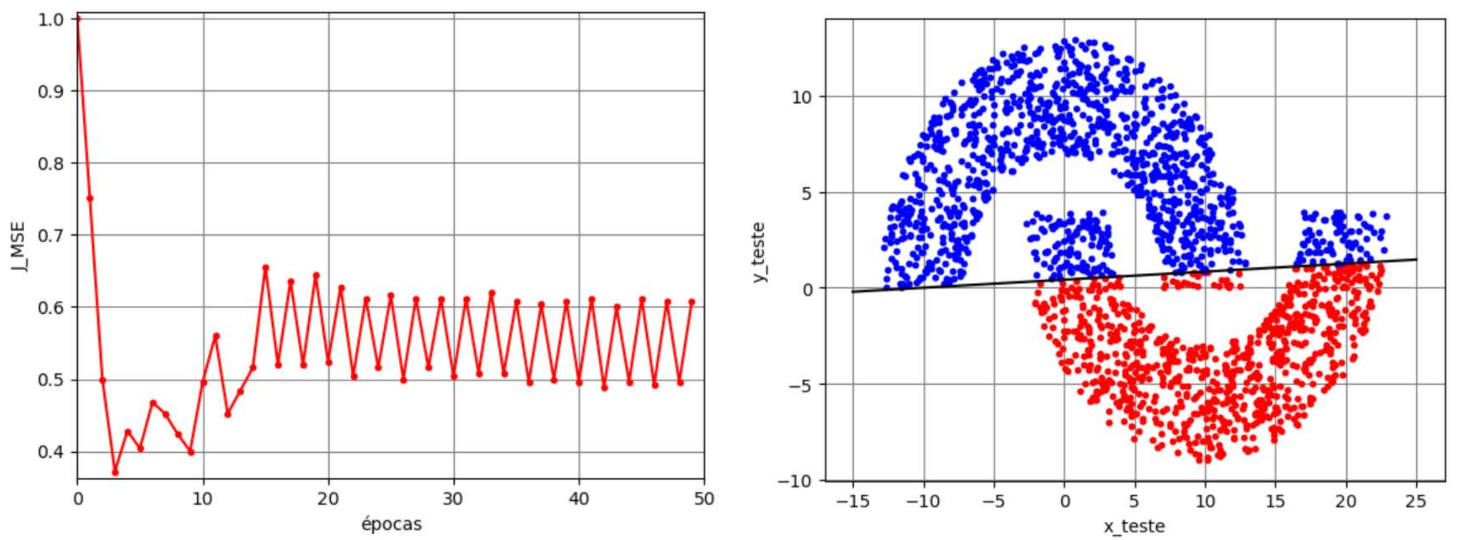
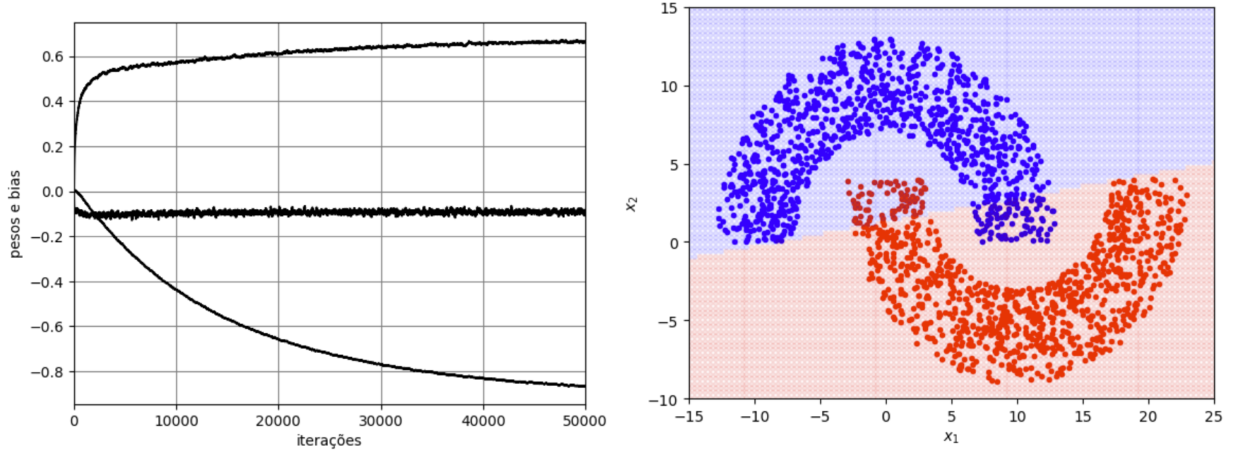
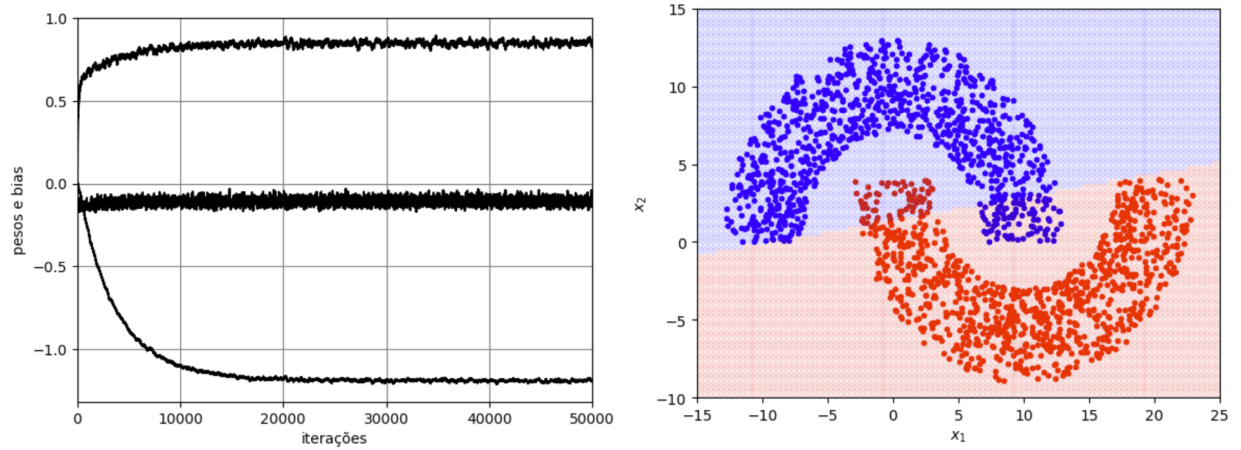
Voltando ao exemplo das meias-luas, vamos considerar agora a solução obtida pelo perceptron de Rosenblatt no modo de treinamento batch com \(M=2\) e considerando \(\eta=10^{-3}\), \(N_t=5000\), \(N_b=N_t\) e \(N_e=50\). Na Figura 5 são mostrados a função custo ao longo das épocas, os dados de teste e a separação linear das regiões no caso de \(r_2=1\). Observa-se neste caso que a função custo converge para zero e a separação obtida proporciona uma solução com taxa de erro nula. Para \(r_2=-4\), uma condição que viola a separabilidade linear, os resultados estão mostrados na Figura 6. Neste caso, observa-se que a função custo não converge mais para zero. Ela varia continuamente, indicando o “colapso” do algoritmo. Isso faz com que parte dos pontos da Região A sejam classificados erroneamente como pertencentes à Região B e vice-versa ao se utilizar os pesos e bias da última iteração, o que leva a uma taxa de erro de aproximadamente \(12\%\).
Comparando o perceptron de Rosenblatt com o algoritmo LMS, percebe-se que ambos podem ser descritos pelo modelo da Figura 4. A única diferença é a função utilizada na saída do combinador linear. Como vimos, no perceptron de Rosenblatt utiliza-se \(\varphi(v)={\rm sgn}(v)\), enquanto no LMS considera-se \(\varphi(v)=v\). Em termos de convergência, o sinal de erro utilizado no perceptron de Rosenblatt é limitado, pois \(e(n)\in \{-2,\; 0,\; 2\}\), o que não ocorre no algoritmo LMS. Isso faz com que o perceptron de Rosenblatt não sofra divergência desde que as entradas sejam limitadas. O mesmo não se pode afirmar sobre o algoritmo LMS, pois o sinal de erro não é limitado. Dependendo do valor do passo de adaptação \(\eta\), o LMS pode divergir. Apesar dessa diferença, ambos levam a fronteiras de separação que são retas (ou hiperplanos no caso em que \(M\geq 2\)). Essas soluções são boas apenas quando há separabilidade linear, o que no exemplo das meias-luas ocorre para \(r_2=1\), mas não ocorre para \(r_2=-4\). Para gerar uma fronteira não linear, podemos usar uma rede neural, como será visto posteriormente. Antes de vermos que o perceptron de Rosenblatt é um dos primeiros modelos de neurônio, unidade básica de uma rede neural, vamos tratar a seguir da regressão logística.
Regressão logística para classificação binária
A adaptação dos pesos do perceptron de Rosenblatt não levam em conta a derivada da função \(\varphi(v)\), uma vez que essa função tem derivada nula para \(v\neq 0\) e não é definida para \(v=0\). Em vez de usar a função sinal no perceptron de Rosenblatt, poderíamos considerar uma função \(\varphi(v)\) com derivada definida e não nula para todo \(v\). Neste caso, teríamos \[ e(n)=d(n)-\varphi({\mathbf{x}^{\rm T}}(n)\mathbf{w}(n-1))=d(n)-\varphi(v(n))=d(n)-y(n), \] cuja derivada em relação a \(\mathbf{w}(n-1)\) é \[ \frac{\partial e(n)}{\partial \mathbf{w}(n-1)}=-\frac{\partial \varphi(\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1))}{\partial \mathbf{w}(n-1)}=-\mathbf{x}(n)\,{\varphi'}(v(n)). \] Considerando a minimização do erro quadrático instantâneo como no LMS, temos o vetor gradiente dado por \[ \widehat{\boldsymbol{\nabla}}_{\mathbf{w}}J_{\text{MSE}}=2e(n)\frac{\partial e(n)}{\partial \mathbf{w}(n-1)}=-2e(n)\,{\varphi'}(v(n))\,\mathbf{x}(n). \] Assim, o vetor de pesos no modo estocástico deve ser adaptado como \[\begin{equation*} \fbox{$\displaystyle \mathbf{w}(n)=\mathbf{w}(n-1)+\eta\, e(n)\,{\varphi'}(v(n))\,\mathbf{x}(n). $} \end{equation*}\]
A minimização do erro quadrático pode levar o algoritmo a ficar parado em mínimos locais. Uma alternativa é usar a entropia cruzada, definida como \[ J_{\rm EC} = - \left[ d(n) \ln\left({y(n)}\right) + [1 - d(n)] \ln{\left(1 -y(n)\right)}\right]. \] Lembrando que \(v(n)=\mathbf{x}^{\rm T}(n)\mathbf{w}(n-1)\) e que \(y(n)=\varphi(v(n))\), chega-se ao seguinte gradiente \[ \begin{align*} \widehat{\boldsymbol{\nabla}}_{\mathbf{w}}J_{\text{EC}}=&-\frac{d(n)}{y(n)}\frac{\partial y(n)}{\partial \mathbf{w}(n-1)}+\frac{1-d(n)}{1-y(n)}\frac{\partial y(n)}{\partial \mathbf{w}(n-1)}\nonumber\\ =&-\frac{e(n)}{y(n)(1-y(n))}\frac{\partial y(n)}{\partial \mathbf{w}(n-1)}\nonumber\\ =&-\frac{e(n)}{y(n)(1-y(n))}\,\varphi'(v(n))\,\mathbf{x}(n).\nonumber \end{align*} \] Assim, o vetor de pesos no modo estocástico deve ser adaptado como \[\begin{equation*} \fbox{$\displaystyle \mathbf{w}(n)=\mathbf{w}(n-1)+\eta\, \frac{e(n)\varphi'(v(n))}{y(n)(1-y(n))}\mathbf{x}(n). $} \end{equation*}\]
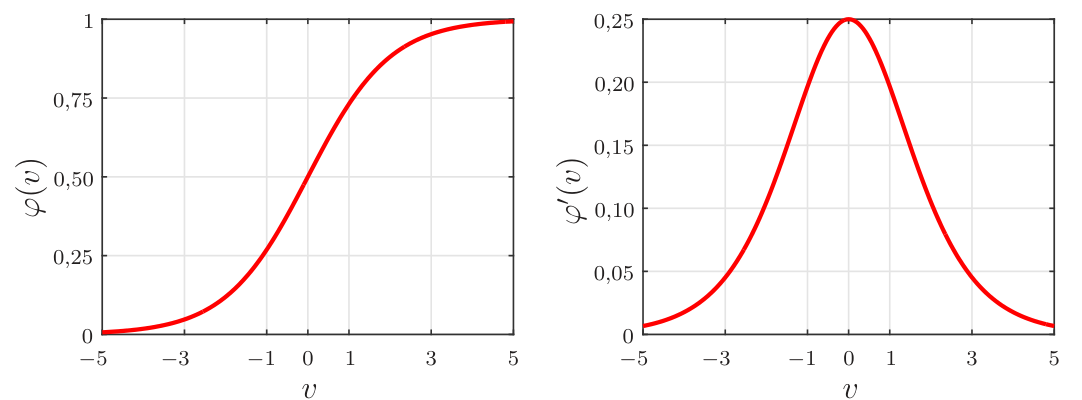
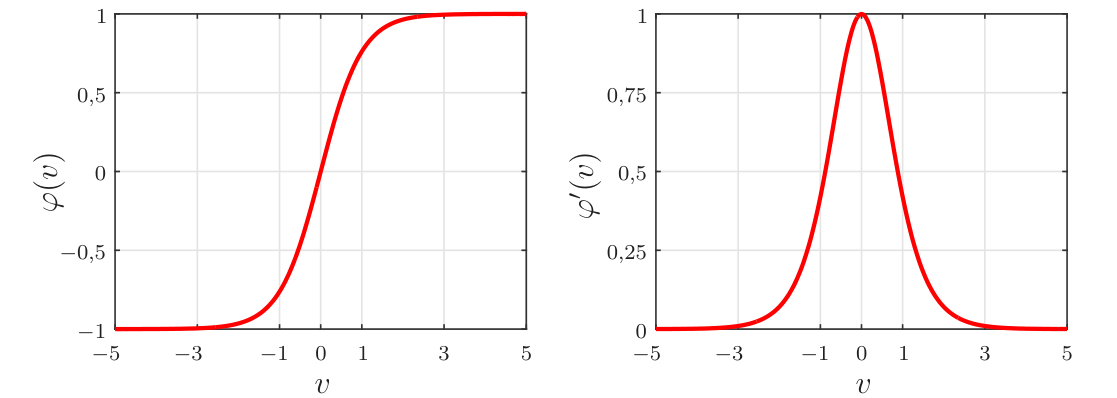
Em um problema de classificação binária com rótulos iguais a 0 ou 1, uma possível candidata para a função \(\varphi(\cdot)\) que apresenta derivada não nula e definida em todos os pontos é a função sigmoidal, também conhecida como função logística. Essa função é definida como \[\begin{equation*} \fbox{$\displaystyle \varphi(v)={\rm sgm}(v)=\displaystyle\frac{1}{1+e^{-v}} $} \end{equation*}\] e tem derivada dada por \[\begin{equation*} \fbox{$\displaystyle \varphi'(v)=\frac{\rm d}{{\rm d}v}{\rm sgm}(v)=\displaystyle \frac{e^{-v}}{\left[1+e^{-v}\right]^2}= \varphi(v)[1-\varphi(v)]=y(1-y), $} \end{equation*}\] em que se usou o fato da saída do neurônio ser \(y=\varphi(v)\). Na Figura 7 são mostrados gráficos da função sigmoidal e de sua derivada. Pode-se observar que a saída do neurônio com função sigmoidal fica no intervalo \([0,\; 1]\). Caso os rótulos sejam iguais a \(-1\) e \(1\), pode-se considerar a função tangente hiperbólica, dada por \[\begin{equation*} \fbox{$\displaystyle \varphi(v)={\rm tanh}(v)=\frac{e^{v}-e^{-v}}{e^{v}+e^{-v}}, $} \end{equation*}\] cuja derivada é \[\begin{equation*} \fbox{$\displaystyle \varphi'(v)=\frac{\rm d}{{\rm d}v}{\rm tanh}(v)=\left[1-{\rm tanh}^2(v)\right]=(1-y)(1+y), $} \end{equation*}\] em que se usou o fato da saída do neurônio ser igual a \(y={\rm tanh}(v)\). Na Figura 8 são mostrados gráficos da tangente hiperbólica e de sua derivada.
Vamos agora obter quatro formas de adaptar os pesos levando em conta as funções logística (sgm) e tangente hiperbólica (tanh) e as funções custo do erro quadrático médio (MSE) e da entropia cruzada (EC): \[ \begin{align*} &\text{MSE, sgm:}\;\;\; \mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)y(n)[1-y(n)]\mathbf{x}(n)\\ &\text{EC, sgm:}\;\;\;\;\;\, \mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)\mathbf{x}(n)\\ &\text{MSE, tanh:}\;\; \mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)[1+y(n)][1-y(n)]\mathbf{x}(n)\\ &\text{EC, tanh:}\;\;\;\;\, \mathbf{w}(n)=\mathbf{w}(n-1)+\eta e(n)\!\left(1+\frac{1}{y(n)}\right)\mathbf{x}(n). \end{align*} \] A equação obtida com EC e sgm é conhecida na literatura como regressão logística para o caso binário. As demais podem ser interpretadas como variantes. Cabe observar que na equação obtida com EC e tanh aparece o termo \(1/y(n)\), o que pode levar a divisão por \(0\). Para evitar isso, pode-se somar uma constante pequena em \(y(n),\) o que acaba alterando a dinâmica do algoritmo. Por isso, essa equação não é muito utilizada e o que se faz é mapear os rótulos iguais a \(-1\) em \(0\) para se utilizar as versões do algoritmo obtidas com a função logística.
Para exemplificar, vamos considerar novamente o problema de classificação binária com as meias-luas com \(r_1=10\), \(r_2=-4\) e \(r_3=6\), mas agora os rótulos da Região B foram mapeados de \(-1\) para \(0\) a fim de se utilizar as equações obtidas anteriormente com a função logística. Os resultados utilizando o modo de treinamento mini-batch podem ser vistos na Figura 9 e na Figura 10, considerando a minimização do MSE e da EC, respectivamente. Os pesos e bias obtidos na minimização de cada função custo são diferentes, mas a separação das regiões são similares e levam a uma taxa de erro de aproximadamente \(8\%\). Apesar dessa taxa ser um pouco menor que a obtida com o neurônio de Rosenblatt, a separação continua linear.
Na literatura a regressão logística é abordada sob o ponto de vista probabilístico como, por exemplo, em (Bishop 2006). Nessa referência, também é abordado o caso multiclasse.
O neurônio biológico e um pouco de história
No início do século passado, o médico e histologista espanhol Ramón y Cajál foi o primeiro a introduzir a ideia dos neurônios como unidades básicas do sistema nervoso. Os neurônios são células altamente especializadas na transmissão de informações na forma de pulsos nervosos. As ligações entre os neurônios são chamadas de sinapses, que tem por função enviar sinais por transmissões sinápticas para ocorrer ações específicas no corpo. A taxa dessas transmissões é considerada baixa quando comparada com portas lógicas de silício. Eventos em um chip de silício acontecem na faixa de nanossegundos, enquanto os eventos neurais acontecem na faixa de milissegundos. No entanto, essa taxa “baixa” é compensada pelo impressionante número de neurônios existentes no sistema nervoso humano, estimado em mais de 86 bilhões. Em termos de sinapses, esse número aumenta para mais de 60 trilhões. O resultado final é que o cérebro é uma estrutura extremamente eficiente.
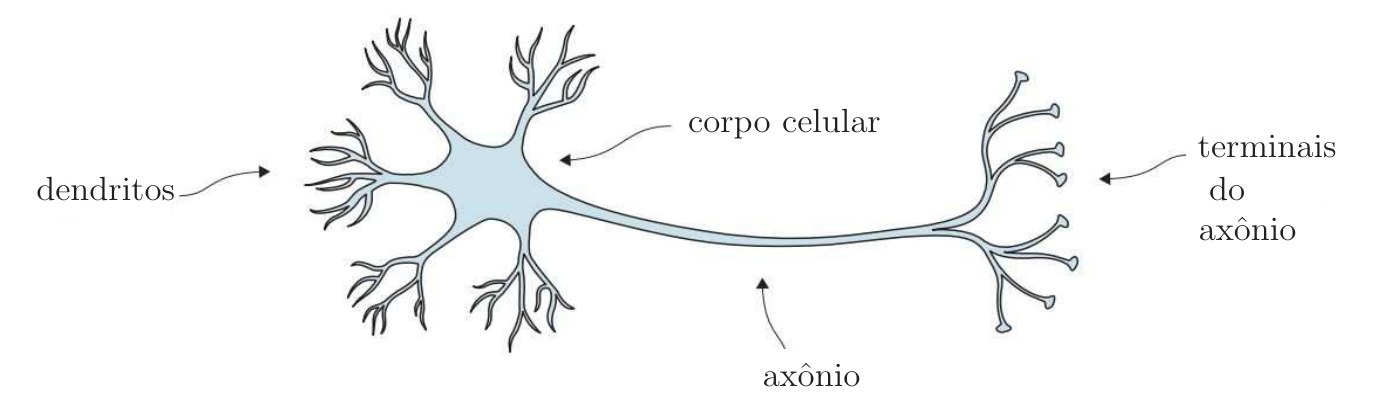
O neurônio biológico está esquematizado na Figura 11. A atividade do neurônio é caracterizada por pulsos elétricos da ordem de milivolts e duração da ordem de milissegundos. Ele recebe esses pulsos de outros neurônios pelos seus dendritos. Se o sinal acumulado exceder um certo valor, um pulso é enviado via axônio aos seus terminais, que por sua vez, se acoplam a outros neurônios. Grosso modo, a computação realizada por um neurônio na sua saída (no seu axônio) pode ser resumida na frequência dos pulsos. Se houver poucos pulsos por unidade de tempo, o neurônio é considerado pouco ativo. Em contrapartida, se ele tiver muitos pulsos por unidade de tempo, haverá mais estímulos sinápticos e o músculo que o neurônio controla, por exemplo, é forçado a uma atividade maior.
Redes neurais surgiram para buscar modelar o cérebro humano. Nos anos de surgimento das redes neurais (1943-1960), vários pesquisadores se destacam por suas contribuições pioneiras (Haykin 2009):
- McCulloch e Pitts (1943) por introduzirem a ideia de redes neurais como máquinas de computação;
- Hebb (1949) por postular a primeira regra de aprendizagem auto-organizada;
- Rosenblatt (1958) por propor o perceptron como o primeiro modelo de aprendizagem supervisionada;
- Widrow e Hoff (1960) por propor o Adaline (adaptive linear element), que deu origem ao algoritmo LMS.
Inspirado no funcionamento do neurônio biológico, Rosenblatt propôs o modelo de neurônio artificial, chamado de perceptron, como ilustrado na Figura 4. O neurônio biológico recebe vários estímulos de outros neurônios que chegam por seus dendritos, esses estímulos são então acumulados e se exceder um limiar, o neurônio gera um estímulo no seu axônio que são transmitidos a outros neurônios. No modelo matemático de Rosenblatt, esses estímulos são representados pelo vetor de entrada \(\mathbf{x}(n)\) e o acúmulo dos estímulos pela soma ponderada da entrada com os pesos, gerando o sinal \(v(n)\). Se \(v(n)<0\), o neurônio estará em repouso. Caso contrário, estará ativo e um novo estímulo, representado por \(y(n)\), é gerado. Aqui cabe uma observação: para representar o neurônio em repouso, talvez fosse mais adequado considerar a função degrau (função de Heaviside) em vez da função sinal. Assim, \(y(n)=0\) para \(v(n)<0\). No entanto, pensando na implementação do modelo com um circuito analógico, pode ser mais adequado considerar uma tensão negativa em vez de uma tensão nula para representar o repouso e para isso, a função sinal se mostrou mais adequada.
Em julho de 1958, o escritório de Pesquisa Naval dos EUA revelou uma invenção notável. Um IBM 704, um computador de 5 toneladas que ocupava uma sala, foi alimentado com uma série de cartões perfurados. Após 50 tentativas, o computador aprendeu a distinguir os cartões marcados à esquerda dos cartões marcados à direita. Foi uma demonstração do perceptron de Rosenblatt, a primeira máquina capaz de ter uma ideia original. Na época, Rosenblatt era psicólogo pesquisador e engenheiro de projetos no Laboratório Aeronáutico da Cornell em Buffalo, Nova York. “As histórias sobre a criação de máquinas com qualidades humanas têm sido fascinantes em ficção científica. No entanto, estamos prestes a testemunhar o nascimento de tal máquina - uma máquina capaz de perceber, reconhecer e identificar seus arredores sem qualquer treinamento ou controle humano”, escreveu Rosenblatt em 1958. Ele estava certo, mas levou aproximadamente meio século para vermos isso acontecer. Na Figura 12, são mostradas uma imagem do título da publicação de Rosenblatt de 1958 e uma foto de Rosenblatt em 1960 com seu perceptron chamado de Mark I, uma máquina eletromecânica implementava os pesos adaptativos por meio de potenciômetros que eram ajustados por atuadores.

Desde 1960, muita pesquisa foi feita com o objetivo de melhorar o modelo do cérebro humano. Apesar dos inúmeros avanços, ainda estamos longe de termos um sistema que consiga modelar de maneira precisa o cérebro, devido à sua alta complexidade e eficiência. Apesar das redes neurais artificiais serem inspiradas no funcionamento do cérebro, vamos encará-las como sistemas não lineares que podem ser aplicados como soluções eficientes em problemas de regressão e classificação.
Uma sugestão de vídeo sobre o surgimento das redes neurais é o The man who forever changed artificial intelligence.
Quem quiser se aprofundar em modelos de neurônios e do cérebro humano já que esse assunto está fora do escopo deste curso, sugerimos o livro (Gerstner et al. 2014).
Referências
Notas de rodapé
Como no caso do algoritmo LMS no modo mini-batch, inserimos aqui o índice \(m-1\) aos vetores que foram calculados com os dados da posição \(\ell\) e pesos \(\mathbf{w}(m-1)\).↩︎